 By Emil Stenqvist in Education • May 23, 2018
By Emil Stenqvist in Education • May 23, 2018
Structural Tokenization Using Simple Heuristics
For the Unomaly 2.28 release, we have completely reworked our tokenizer in order to pick up on nested structures and key-value pairs in the unstructured log data that we ingest — without any schema specification. To make it understandable we’ll go through a bit of how Unomaly works and then delve into the technical details of the new structural tokenizer.
TL;DR
- Unomaly automatically clusters event logs and categorizes them as normal or anomalous, according to baseline of all logs it’s seen before.
- The algorithm is format agnostic, and simple heuristics of what log messages typically look like has taken us a long way and proven more flexible than one might think.
- However, we wanted to understand fragments of structured data in the logs better, such as: sent message {“from”:”jane”,”to”:[”joe”,”anne”,”peter”]}
- To do this, we created a structural tokenizer that detects and parses structured data spliced into otherwise unstructured log messages.
- In the process, we learned new ways of looking at the problem as one of string and sequence matching — opening up many more paths of further improvement.
Turning water into wine — the Unomaly way
From a high-level perspective, Unomaly is a tool that ingests a log stream, and reduces it into aggregates of repeating events, and anomalies — which by definition are rare. This turns an overwhelming stream of events into something that can one can grasp and stay on top of. To see why this is useful, let’s see where log messages come from. Somewhere in a program, there’s a line this:
if ok {
log.Info(“This is fine.”)
} else {
log.Fatalf(“This is not fine.”)
}That will produce something like this:
INFO 2018–01–24T10:49:54Z This is fine. pid=39067 pkg=main
Over time, the program will potentially emit millions of This is fine. events. But, because it looks slightly different each time (in this case the timestamp and the PID), it’s not trivial to map these instances, to a single canonical event — the one line in the source code. You’d need a taxonomy of all events that your system may emit, which has to cover all third-party tools and every piece of software you write, by every team, and be continuously kept up to date. A lot of work!
And this is one of the core things Unomaly does: it performs an online clustering of the events it receives, and learns the different event types it has seen statistically, rather than from a definition. Once it has seen enough data, it can continuously describe the log stream in this way instead:
- “Event X happened 94 times during the past 13 seconds” — aggregation of normal events.
- “Event Y happened at time T: never before seen..” — detecting anomalies.
Since, by definition, the majority of events are normal and repeating, this results in a significant reduction in data.
How do we do that?
It all starts with finding any type of structure in the raw data that it receives. This is done by a tokenizer which turns the raw log message into a sequence of tokens. The example:
INFO 2018–01–24T10:49:54Z This is fine. pid=39067 pkg=main
is tokenized in to:
{
P(“INFO”), D(“ “), P(“2018–01–24T10:49:54Z“), D(“ “),
P(“This”), D(“ “), P(“is”), D(“ “), P(“fine”), D(“. “),
P(“pid=39067”), D(“ “), P(“pkg=main”)
}Where we have two types of tokens, parameters (P) and delimiters (D). The parameters contain the actually contents of the log message, while the delimiters capture the punctuation, and more useful for producing a structure signature for the event, described below. For brevity, we will use the following syntax from hereon:
INFO 2018–01–24T10:49:54Z This is fine. pid=39067 pkg=main
^~~~_^~~~~~~~~~~~~~~~~~~~_^~~~_^~_^~~~__^~~~~~~~~_^~~~~~~~
where ^~~~~~~ = parameter
__ = delimiter
From the token sequence, we can derive:
- An event structure: A hash that is characteristic for the event type. For the above example, this is essentially a hash of the following:
{P(type=word), D(“ “), P(type=timestamp), P(type=word), D(“ “), P(type=word), D(“ “), P(type=word), D(“. “), P(type=word), D(“ “), P(type=word)}2. An event profile: The parameter values for a particular instance of the event. For the same example, this would be:
{“INFO”, “2018–01–24T10:49:54Z”, “This”, “is”, “fine”, “pid”, 39067, “pkg”, “main”}Anything we can derive in the tokenizer and include in the structure will improve the clustering efficiency. For the tokenizer to work well we must be liberal in what we accept, and opportunistically try to find any meaningful information in the data: unique identifiers, JSON fragments, URLs, apparent key-value pairs, etc.
Our love affair with Ragel
In the beginning of time, at the heart of Unomaly you would find this regex, constituting our first tokenizer:
(\s*\S*?)(\w+\S*\w|\w+)(\S*)|(\s\S+)
This was hard to extend upon and, more importantly, it was slow as a turtle. For example, recognizing objects such as timestamps required work arounds.
Then we found Ragel — a parser generator, which allows you to write finite state machines that traverse strings at blazing speed and with high flexibility. You define machines like this:
hex_number = ( ‘0’ [xX] [a-fA-F0–9]+ | [0–9]+ [0–9a-fA-F]+ );
Which you can then combine like LEGO blocks, in order to create more complex machines. The real power comes with the ability to interact with the host language, in our case Go, in order to control the machine, or store things that you have matched. For example:
// This is Ragel.
(hex_number | dec_number | oct_number)+ => {
// This is Go code.
state.tokens.add(ts, te, data, numberToken)
};
Upon discovering Ragel we rewrote our tokenizer in it, which resulted in a multiple- orders-of-magnitude speedup from the old regex matcher. Writing the tokenizer as a finite state machine has given us a lot of flexibility, and adhere to our design principle: try and hard code as little possible, and be maximally agnostic to different log formats. And that principle has taken a long way — but as with every 80/20 type of simplification: it sometimes needs dealing with the edge cases.
Issues with old tokenizer
Let’s consider this log:
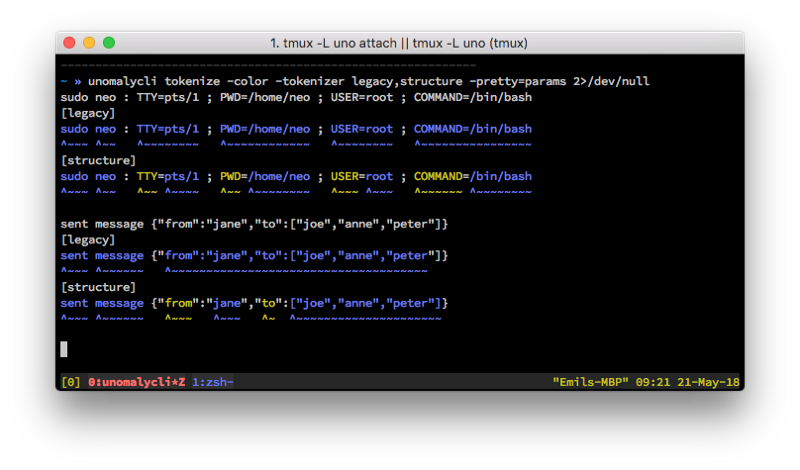
sudo neo : TTY=pts/1 ; PWD=/home/neo ; USER=root ; COMMAND=/bin/bash
^~~~_^~~___^~~~~~~~~___^~~~~~~~~~~~~___^~~~~~~~~___^~~~~~~~~~~~~~~~~
Here, notice how a KEY=value pair becomes a single token — even though keys and values are two different things — one being static, the other variable, they will be analyzed as one.
Another issue, is if the log contains JSON:
sent message {“from”:”jane”,”to”:[”joe”,”anne”,”peter”]}
^~~~_^~~~~~~___^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~___The JSON blob becomes a single token, even though it’d be more sensical to analyse the to and the from fields separately. Had it contained spaces we’d have another problem:
sent message {“from”: ”jane”, ”to”: [”joe”, ”anne”, ”peter”]}
^~~~_^~~~~~~___^~~~____^~~~____^~_____^~~____^~~~____^~~~~___Notice the value of to is not represented as a list of things, but completely unrelated parameters, even though we’d like to capture it as something like sent message {“from”: ”jane”, ”to”: <recipients>}.
A similar issue is that of deeply nested JSON structures that also produce tokens in an uncontrolled manner, leading to false positives . What we prefer is a kind of depth limit, beyond which we treat the rest as a single token. Our only remedy for this was to turn the whole JSON fragment into a single token — no matter how much information it contained. This kept the anomalies down, but was essentially coping out and saying: we’ll just call this random and forget about it — even though there might be some valuable data inside them.
With these examples in mind, and customers in need — it was clear that the tokenizer needed to understand things such as JSON objects or key-value pairs or lists. We needed a structural tokenizer.
Introducing: Structural tokenization
Over time a lot of cruft had accumulated in the old tokenizer — workarounds to produce good tokens, e.g. group tokens wrapped in double quotes. The first thing we did was just throw this out and simplify it to just split by spaces and delimiter tokens:
, ; : = # | * “ ‘ { } ( ) [ ] < >We decided to stick with Ragel and Go but introduced two new concepts into the tokenizer:
- Key-value recognition: Keys are now their own token type.
- Pairing of structural delimiters: we try and find open and closing pairs of delimiters such as { } or ( ) and try to parse what’s inside as a nested structure. This also allows us to impose a (configurable) depth limit, mitigating false positives.
The bold parts of the following examples are tokenized as a key:
- key=value non_key = value not/a/key=value “is/a/key”=value
- (key = value, non_key: value)
- { ‘key’: “value”, key: {non_key = value} }
With this knowledge, we decided to include the keys found in a log as part of its structure signature. This means we don’t have to learn that they are static, and as a result we see a quicker learning rate.
The second issue we solve with this is collapsing, or grouping, of fragments into meaningful tokens. The bold parts of the following examples are collapsed into one token:
- {key: {key: {key: value}}}
- {key: [item, item, item], key: (item (item item item))}
- Non-json lists [are, not, collapsed] {[item, item]}
- Any (type [of <structure can be collapsed>])
- {structures (are [balanced (inside ] collapsed ) ] tokens ) }
As simple as it might seem, these simples heuristics seem to capture the majority of problematic logs we have encountered. We are excited to see how this addition will fare in practice! Also, we see that more of these heuristics can be added over time — and maybe even mined from the data in a post-processing step.
[before]
sudo neo : TTY=pts/1 ; PWD=/home/neo ; USER=root ; COMMAND=/bin/bash
^~~~_^~~___^~~~~~~~~___^~~~~~~~~~~~~___^~~~~~~~~___^~~~~~~~~~~~~~~~~
[after]
sudo neo : TTY=pts/1 ; PWD=/home/neo ; USER=root ; COMMAND=/bin/bash
^~~~_^~~___^~~_^~~~~___^~~_^~~~~~~~~___^~~~_^~~~___^~~~~~~_^~~~~~~~~
Notice how the keys and the values are now broken apart. Now let’s consider an example with JSON included as well:
[before]
sent message {“from”:”jane”,”to”:[”joe”,”anne”,”peter”]}
^~~~_^~~~~~~___^~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~___
[after]
sent message {“from”:”jane”,”to”:[”joe”,”anne”,”peter”]}
^~~~_^~~~~~~__^~~~~~_^~~~~~_^~~~_^~~~~~~~~~~~~~~~~~~~~~_
And the wonderful thing is that this does not require the input to be perfectly valid JSON, but just anything looks a bit like it.
Conclusion
As the famous saying goes, if you can phrase a problem correctly — you’re already halfway to solving it. For us, that was the realization that the search for textual anomalies, boils down to a string and sequence matching problem. If we can create good clusters of logs, and quickly match new logs to them — we have what we need. This opened up a whole body of existing knowledge that we could look at. Do we even need tokenization in the first place? Maybe not! This led us to experiment with new methods less bound to our existing approach:
- Running it through DNA sequencing algorithms — slow to train, but great results!
- Locally sensitive hashing
- Nearest neighbour search — with a great room for being creative in the feature vectors we feed it!
Whatever paths we go down, we don’t see a need for replacing the existing algorithm, but rather augment it by introducing a parallel pipeline where multiple methods are applied. So, we will most definitely have more to say about this!
This was our first release post — where we pick something that we find especially exciting about a release, and make a post about.
With that, stay tuned and, if you’re living in the northern Hemisphere, be sure to enjoy springtime!