 By Emil Stenqvist in Technology • January 6, 2019
By Emil Stenqvist in Technology • January 6, 2019
uno: a uniq like CLI tool for log data
Update 1 July 2019:
We've launched a free web app version of Uno, which will let you upload your log files for a quick debug. Check it out at FeedUno.io.
TL;DR
- Due to the volume and repetitive nature of log data it's hard to actually review it and spot issues - relevant things are lost in the flood of normal even looking at the logs from a single laptop.
- We built a small tool called uno, that's like uniq but for logs which helps you filter out the normal and only outputs things that are new - i.e. anomalies.
- Proof-of-concept: plugging in a USB memory stick and seeing uno immediately highlight this new event, see video.
- This turned out to be a great way to illustrate the core concept behind Unomaly: taking a stream of logs and separating it into normal and anomalous.
Introduction
The vast majority of logs produced end up in storage or being deleted without ever being looked at. Unless, of course, there is an incident and then we spend time trying to figure out what they were trying to tell us while we were ignoring them. We are overwhelmed by log data even though it contains highly valuable information. In trying to tackle this issue, I decided to take a look at the logs being produced by my laptop to see if there was a solution to effectively work with this data:
$ sudo log show --last 1d | wc
1372994 16723356 212231040
Over 200 MB worth of log data in just in one day. And I haven't done anything more spectacular than listening to music, coding, writing a blog post and of course some Facebook browsing.
Now, let's say something actually happens: I pair with a new Bluetooth device or my SSD starts going bad – how would I spot this in the logs? I couldn't possibly review the full dataset daily.
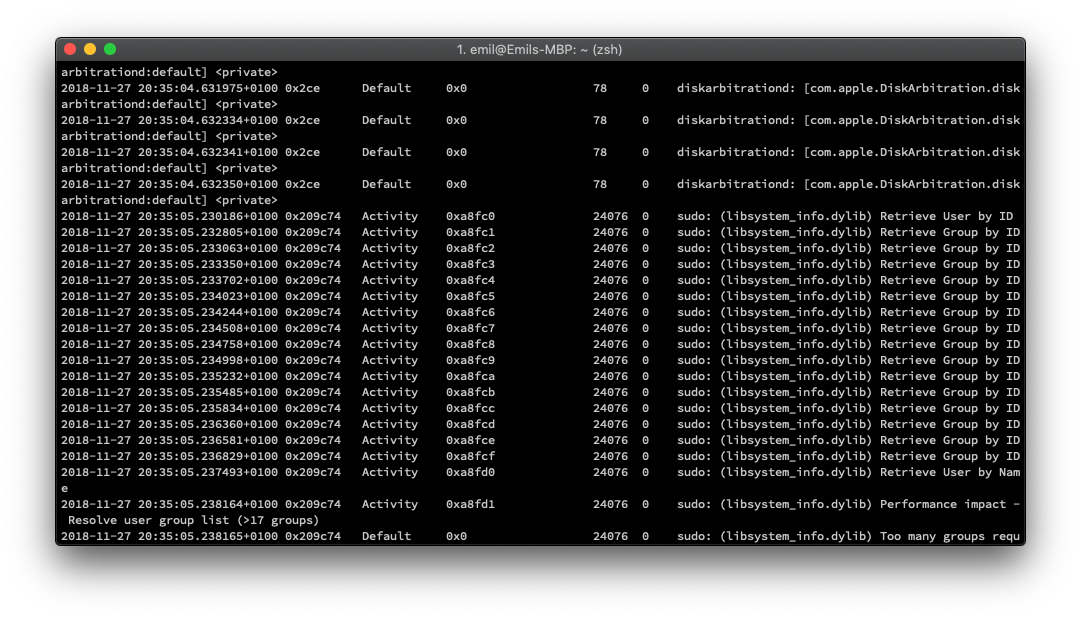
Looking at a sample of the logs it's obvious that there is both repetition and structure in this data – similarly structured messages repeat with different parameters, dates, numbers, file names, etc. This seems like a great candidate for some automation, let's see what we can do!
uno: uniq on steroids
We built uno, a small tool similar to uniq (the UNIX CLI tool that removes duplicates) - but with fuzziness. uno considers two lines to be equal if their edit distance is less than a specified threshold, by default set to 30%. It reads from stdin and prints the deduplicated lines to stdout.
To start out I piped my laptop log stream through uno. To see the effect I'm showing the unfiltered log stream on the right and the one filtered through uno on the left. We should expect the left one to get quieter over time as repeating lines are suppressed.
As expected the filtered log stream quickly becomes noticeably more quiet than the unfiltered one, especially as I do some Spotlight searching to trigger more logging. The red lines are stats updates and in the above we can see that:
13674 lines seen(51/s), 514 uniques, reduction: 0.96 [...]
uno filtered away 96% of the data. How can 13674 events be reduced to 514 distinct types? Well, the number of logs generated by a program over time is unbounded while the number of log statements in the program that creates those logs is finite and typically orders of magnitude smaller than the generated log volume, over time.
Now, let's return to the originally posed problem: how can we spot anything out of the ordinary in this log stream? To do this, I want to feed uno a large amount of logs to get a good baseline – i.e. making sure it has seen most of the normal logs and hence will not output them anymore. So I took the days worth of logs from my laptop, ~1.4M events totalling 209 MB and fed it through uno. I saved the resulting 12,495 distinct log lines into a baseline which can then be preloaded when we feed it the live log stream.
As expected, when I start uno with the baseline and don't do anything with my laptop, it is almost silent since everything that comes in has been seen before.
So instead, let's say I do something that I know is not part of the baseline: plug in a USB memory stick. (I haven't done that in the past 24 hours, so the logs should contain no records of it)
What is lost in the noise on the right clearly stands out on the left where we've filtered out all the normal stuff. Just through a glance one can see that "something with a USB memory" has happened – enough to get our attention and look into it. The remarkable thing is that we did with this without any hardcoded knowledge of what to look for. This was highlighted by just filtering away the normal and looking at the remainder, or the anomalies.
How this is useful
What is the first question you ask yourself when investigating an issue? What is different from before? Back when it worked as intended.
Troubleshooting is largely a process of repeated elimination of irrelevant data in order to single out what is different. But you don't know what that something is so you can't search for it! This makes it time-consuming and hard to perform as a proactive measure.
What I've shown above is a way of automating this process of eliminating the normal. This can be used for a number things, such as:
- Notifying: Since you're alerted of anything unusual you have better chance of being proactive and spotting issues before they have consequences.
- Change management: If you know that there will be changes, e.g. during a deploy, you can look at the anomalies output to immediately see the effect of those changes.
- Profiling: The baseline is essentially a taxonomy of your log data and what is normal which can help getting a picture of what goes on in your systems.
And, most importantly, note how this is possible without keeping your monitoring in sync with your log producers – as in having patterns for every log type that is received, or rules for alerting on errors. For internal software this means constantly keeping up with the development team and knowing what signals to look for. In a world of distributed teams and continuous deployment this is a major point of failure: it will be overlooked, and it incentivises being resistant to making changes in the first place.
This way of looking at log data in terms of anomalies is what Unomaly is built around and we'll explore the concept more in subsequent posts.
How does uno relate to Unomaly?
uno is a free barebones CLI tool that we first built to illustrate the core concept of Unomaly. It uses a different algorithm, but hold tons of value on its own. Also, it's great fun to play around with. Tip: pipe your dev logs through it.
With all that said, here it is for you to play around with:
(Note: the preloading feature is experimental and not included in the public version)
We'd love to hear your comments! You can tweet me @svammel (post and demo author), or @alexandrepesant (uno author) or any of our colleagues @unomaly.